In GNUSDR werden die Daten in Blöcken verarbeitet. In einem GNU Radio-Flowgraph besteht jeder Block aus einem oder mehreren Eingängen und Ausgängen, die Datenströme (Samples) weiterleiten.
Der Scheduler sorgt dafür, dass die Datenflüsse zwischen den Blöcken koordiniert werden. Dazu überwacht er kontinuierlich, ob ein Block ausreichend Daten erhalten hat, um verarbeitet zu werden, und ob genug Platz im Ausgabepuffer ist, um die verarbeiteten Daten weiterzugeben. Er stellt sicher, dass ein Block erst dann ausgeführt wird, wenn ausreichend Eingabedaten zur Verfügung stehen und er koordiniert die Übergabe der Daten vom Ausgabepuffer in den Eingabepuffer eines nachfolgenden Blocks. Die Verarbeitung der Daten in den Blöcken erfolgt möglichst parallel, um die Leistungfähigkeit der Rechnerinfrastruktur optimal auszunutzen.
Die Verarbeitung erfolgt dabei in verschiedenen Threads, um parallel auf mehreren CPU Kernen zu arbeiten, so dass eine optimale Lastverteilung erreicht wird.
Input
Wie oben schrieben, erhält ein Block als Input einen Buffer mit Daten, die einen Teil des Signals abbilden. Blöcke können dabei auch mehrere Inputs haben.
Die Daten sind in unterschiedlichen Typen verfügbar wobei der Datentyp oftmals im Block ausgewählt werden kann.
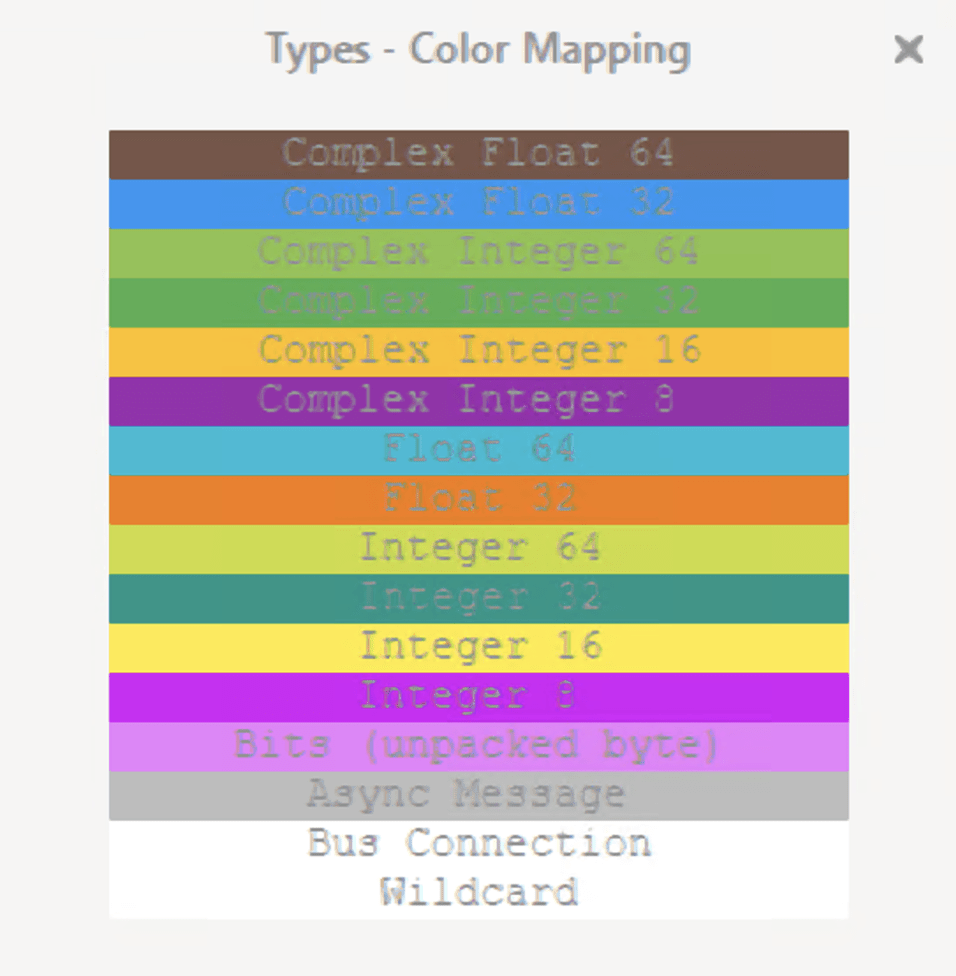
Die Variablentypen sind in GRC farblich gekennzeichnet. Für die Verarbeitung der IQ-Signale kommt der Komplexe Datentyp zum Einsatz. Float und Integer wird je nach Anwendungsfall genutzt.
Zur Konvertierung von Datentypen (z.B. ComplexTo Float) sind Blöcke vorhanden.
Verarbeitung
Die Hauptaufgabe des Blocks besteht darin, eine bestimmte Signalverarbeitungsfunktion auf die eingehenden Daten anzuwenden.
Beispiele:
- Filterung
- Modulation/Demodulation
- Transformation: z.B. eine Fast Fourier Transform
- Decodierung
- Mathematische Operationen
- Benutzerdefinierte Aufgaben
Output
Der Output eines Blocks besteht aus den verarbeiteten Datenströmen, die nach der Anwendung der Signalverarbeitungsoperation zur Verfügung stehen. Die Ausgabe kann ebenfalls in verschiedenen Formen vorliegen, je nach Art des Blocks:
- Einzelner Datenstrom: Nach der Filterung oder Modulation wird ein einzelner Datenstrom (beispielsweise in Form von komplexen Zahlen) ausgegeben.
- Mehrere Datenströme: Manche Blöcke geben mehrere Datenströme aus, z. B. nach einem Splitter oder Multiplexer, um verschiedene Signalanteile getrennt zu verarbeiten.
- Datentypen: Wie beim Input können auch die Ausgabedaten ganzzahlig, gleitkommazahlbasiert oder komplex sein.
Beispiel für die Verarbeitung in einem Block
Der Folgende Custom Block zeigt die grundlegenden Funktionen bei der Verarbeitung von Blöcken anhand des intern generierten Python Codes:
In GRC sieht der Block wie folgt aus:
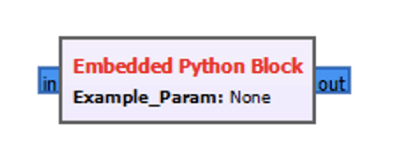
Der Name des Blocks wird beim Aufruf von Block.__init festgelegt:
name=’Embedded Python Block’
Der Example_Param wird dem Block automatisch hinzugefügt, wenn er in der init Funktion definiert wurde:
def __init__(self, example_param=1.0)
"""
<strong>Embedded Python Blocks:</strong>
Each time this file is saved, GRC will instantiate the first class it finds
to get ports and parameters of your block. The arguments to __init__ will
be the parameters. All of them are required to have default values!
"""
import numpy as np
from gnuradio import gr
class blk(gr.sync_block): # other base classes are basic_block, decim_block, interp_block
"""Embedded Python Block example - a simple multiply const"""
def <strong><mark style="background-color:rgba(0, 0, 0, 0)" class="has-inline-color has-vivid-red-color">__init__</mark></strong>(self, example_param=1.0): # only default arguments here
"""arguments to this function show up as parameters in GRC"""
gr.sync_block.__init__(
self,
name='Embedded Python Block', # will show up in GRC
<mark style="background-color:rgba(0, 0, 0, 0)" class="has-inline-color has-vivid-green-cyan-color"><strong>in_sig=[np.complex64],</strong></mark>
<strong><mark style="background-color:rgba(0, 0, 0, 0)" class="has-inline-color has-vivid-cyan-blue-color">out_sig=[np.complex64]</mark></strong>
)
# if an attribute with the same name as a parameter is found,
# a callback is registered (properties work, too).
self.example_param = example_param
def <mark style="background-color:rgba(0, 0, 0, 0)" class="has-inline-color has-vivid-red-color"><strong>work</strong></mark>(self, input_items, output_items):
<mark style="background-color:rgba(0, 0, 0, 0)" class="has-inline-color has-luminous-vivid-amber-color"><strong> """example: multiply with constant"""
output_items[0][:] = input_items[0] * self.example_param</strong></mark>
return <mark style="background-color:rgba(0, 0, 0, 0)" class="has-inline-color has-vivid-cyan-blue-color">len(output_items[0])</mark>Code-Sprache: HTML, XML (xml)In der Init Funktion werden die Input und Output Daten definiert. Hier wird ein Array von Komplexen Zahlen als Input übergeben, der Output besteht ebenfalls aus einem komplexen Array.
Der Verarbeitungsschritt multipliziert jedes Element aus dem Input Array mit einer festen Konstante und befüllt das Output Array.
Input_items und Output_items wird für jeden Ein- und Ausgang separat übergeben. Input_Items [0] enthält deshalb den Input Array für den ersten Eingang.
In Zusammenhang mit der Verarbeitung von Daten in den Blöcken werden häufig auch die Begriffe Vector und Stream verwendet.
Stream
Ein Stream ist dabei ein kontinuierlicher, ununterbrochener Datenstrom, der aus einer Folge von Items besteht, die von Block zu Block im Flowgraph übertragen werden. Der Stream wird in Blöcken gepuffert und dann in Abschnitten durch die work()-Funktion eines Blocks verarbeitet.
Vector
Ein Vector ist feste Anzahl von Datenpunkten, die oft in einem einzigen Schritt als eine Einheit verarbeitet wird. Ein Vector wird in GNU Radio typischerweise verwendet, wenn die Datenmenge bekannt ist und eine feste Struktur hat, z.B. bei FFT-Blöcken.
Die Input und Output Daten eines Blocks sind in der Regel ebenfalls Vectoren. Der Scheduer steuert die blockweise Verarbeitung und übergibt dem Block eine Anzahl von Items in Form eines Vectors..
Eine Signal Source liefert typischerweise einen Stream von Daten, der in Form von Vektoren verarbeitet wird. Jeder Wert im Stream ist dabei ein einzelner Abtastwert. Die zeitliche Komponente wird dabei nicht direkt als separate Dimension gespeichert, sondern ist implizit in der Art und Weise enthalten, wie die Daten abgetastet und verarbeitet werden. Die Sample Rate muss daher bekannt sein, um das Signal zeitlich korrekt aus den Daten zu rekonstruieren.
Für reale Signale, die über eine SDR Source empfangen werden, besteht ein direkter Zusammenhang zwischen der Abtastrate und dem Sampling-Wert.
Wenn man z.B. mit Hilfe der jeweiligen GRC-Blöcke selbst Signale generiert (z.B. Sinuswellen oder Rauschen), fließen die Daten normalerweise nicht in Echtzeit durch den Flowgraph, sondern so schnell, wie die CPU sie verarbeiten kann. Der Throttle Block zwingt den Flowgraph dann dazu, sich an eine vorgegebene Abtastrate zu halten und somit die Verarbeitung an eine reale Geschwindigkeit anzupassen. Er ist demnach bei der Nutzung realer Signale nicht erforderlich.